topic이라는 테이블의 데이터가 1억개가 있다고 가정해보자
이것들을 전부 또는 일부를 수정해야 하는 상황이 발생하면 난감해진다
또한 이름과 직업이 똑같은 사람이 존재한다면 더욱 당황스러울 것이다
그리고 만약 1개의 당 1GB의 데이터를 가지고 있다고 한다면
아주 비싼 Oracle의 비용과 저장공간이 낭비될 것이다.
이러한 극단적인 예시를 해결하기 위해 테이블을 분해하는 방법을 고안하였다.

이런 상황을 해결하기 위해 author라는 테이블을 생성하고 join하여 고유의 번호(id)를 부여해준다
그렇게 하면 이름과 직업이 중복되는 현상을 방지할 수 있고 훨씬 더 빠른 시간안에 수정하는 것도 가능하다.
이전 테이블 분해와 반대로 데이터를 결합하는데
topic 테이블과 author 테이블을 결합하려한다.

위와 같이 하나의 테이블로 되어 하나의 완벽한 테이블이 되었다.
이번에는 SQL Developer로 topic 테이블과 author 테이블을 하나로 합쳐보자
먼저 SQL Developer로 author 테이블을 생성시켜준다. (topic 테이블은 이미 존재)
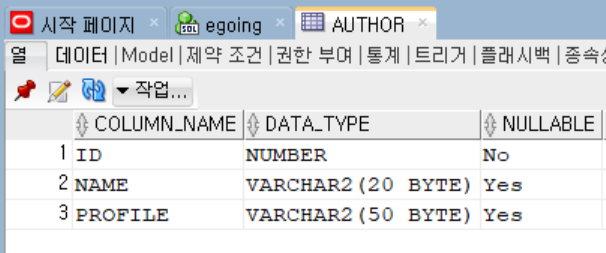
둘의 테이블을 하나로 결합하기 위해 topic 테이블에 AUTHOER_ID를 추가해준다

author_id의 번호를 자동으로 1씩 증가 시켜줄 SEQUENCE(SEQ_AUTHOR)를 생성시켜준다

author의 테이블의 틀을 생성해준다

변경해줄 author_id에 숫자를 기입해준다

이렇게 하면 두 테이블을 합칠 준비가 완료된다.
마지막으로 join문을 통해 topic 테이블을 기준으로 오른쪽에 author 테이블을 붙여준다

이렇게 topic 테이블과 author 테이블은 하나가 되었다.
- 참고) 별명 붙이기
다음과 같이 topic 테이블 기준으로 출력하고 싶을 때 이렇게 출력하면 된다.

하지만 주로 대문자 형태로 사용하는 별명이라는 것을 붙여서 많이 사용하기 때문에 이렇게 사용하는 법도 알면 좋다.

(위 아래 결과 출력은 동일함)
** 정리
topic을 T라는 별명을 지어 topic 테이블을 T로 사용 가능하고
authour를 A라는 별명을 지어 authour 테이블을 A로 사용가능하다
'SQL > Oracle SQL' 카테고리의 다른 글
| Oracle SQL - 9 (SQL Developer 실행 방법) (0) | 2023.09.20 |
|---|---|
| Oracle SQL - 8 (SEQUENCE) (0) | 2023.09.20 |
| Oracle SQL - 7 (PK, Primary Key) (0) | 2023.09.20 |
| Oracle SQL - 6 (행 삭제, CRUD 의 D) (0) | 2023.09.20 |
| Oracle SQL - 5 (행 수정, CRUD 의 U) (0) | 2023.09.20 |



